[EMNLP 2025] VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format
王越千的关于多模态大模型的主动交互的论文《VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format》被EMNLP 2025接收。
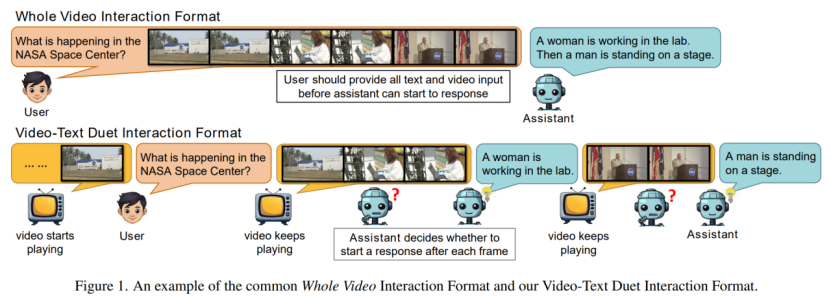
已有视频大语言模型的研究主要集中于模型架构与训练数据,而用户与模型的交互形式却鲜少被深入研究。本文创新性地提出“视频-文本二重奏”交互模式,实现了视频多模态大模型的主动交互(Proactive Interaction),使模型能够在视频流持续播放过程中实现实时对话与响应。为适配这一模式,本文构建了训练数据集MMDuetIT,并设计了MAGQA任务作为实时响应能力的评估基准。实验表明,基于该模式训练的MMDuet模型在时间敏感任务中取得显著性能提升,同时实现了视频播放期间的实时交互能力。这一突破为视频大语言模型在直播解析等实时场景中的应用开辟了新路径。