[EMNLP 2025] AdamS: Momentum Itself Can Be A Normalizer for LLM Pretraining and Post-training
张辉帅,王博涵的关于显存高效的大模型优化算法AdamS的论文《AdamS: Momentum Itself Can Be A Normalizer for LLM Pretraining and Post-training》被EMNLP 2025接收。
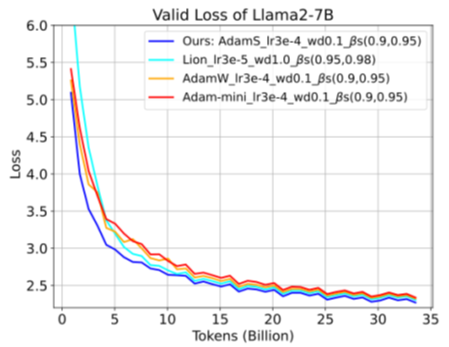
提出 AdamS,作为 Adam 的一种简单而有效的替代方案,适用于大语言模型(LLM)的预训练与后训练。通过引入一种新的分母形式——即动量与当前梯度的加权平方和的平方根——AdamS 消除了对二阶矩估计的需求。因此,AdamS 具备更高的效率,其内存与计算开销与带动量的 SGD 相当,同时在优化性能上优于 AdamW。此外,AdamS 易于采用:它可以直接沿用 AdamW 的超参数设置,并且完全与模型无关,无需修改优化器 API 或网络结构即可无缝集成到现有训练流程中。AdamS 的动机来源于我们观察到 Transformer 目标函数具有 $(L_0, L_1)$ 平滑性性质,其中局部平滑性由梯度幅值所主导,而梯度幅值又可进一步由动量幅值近似。我们给出了严格的理论收敛保证,并提供了超参数选择的实践指南。在实验上,AdamS 在多种任务中表现强劲,包括 GPT-2 与 Llama2(参数规模最高达 13B)的预训练,以及后训练阶段的强化学习任务。凭借其高效性、简洁性与坚实的理论基础,AdamS 成为现有优化器体系中一个颇具吸引力的替代选择。